There's a module for that!Solving hard problems in Drupal architecture and development
Portfolio
WorkBC.ca: Engineering a massive Drupal site
CDQ: Re-engineering a failing Drupal codebase
SSOT: Creating a data API for Drupal consumption
Services
Solution architecture
Module development
Service integration
Content migration
Troubleshooting and optimization
Engineering leadership
About
Hello!
My name is Karim Ratib. I consider myself a software “craftsman”, combining professional programmer, architect, tinkerer, learner, speculator, etc.
I’m also a lifelong music fan, learner, player and programmer. I’m deeply involved in a project called music-i18n, which aims at adding support for worlwide music traditions to open source music software. I’m contributing to FOSS projects and creating my own around this concept - you can check my music demos here.
At ITWorx, the first company I joined fresh out of university, I wrote code for Corel MotionStudio 3D, Adobe Illustrator, Microsoft Outlook, among many others
Contact Me
If you have a project where you think my skills would be valuable, I would love to hear from you!
The more details you include in your message, the more accurately I'll be able to respond. Thanks for your interest.
Please note that clicking Send will open up your email client to actually send the message.
Thanks for getting in touch! I usually answer promptly.
Solution architecture
I design Drupal-based software solutions based on a business problem or a technical specification. I understand the value to be delivered in order to advise on the best technical solution to adopt. As a CMS platform, Drupal is suitable for a wide range of scenarios, but it does not necessarily need to be the only component in the overall architecture, and it can be ill-suited for some problems. Thanks to my decades of experience building Drupal solutions, I can quickly identify how to utilize Drupal’s strengths, and how to avoid its pitfalls. In terms of architecture, I subscribe to the guiding principles of the so-called “Twelve-Factor App”.
Module development
I have been programming Drupal modules since version 4. I have intimate knowledge of the “Drupal Way” as it evolved through the decades. My programming philosophy focuses on simplification and economy to reduce the surface area of bugs and inconsistencies. This means I strive to fully utilize the Drupal API to avoid duplicating functionality, and to produce modules that are good citizens in the platform’s ecosystem. I prefer to write unit tests if at all feasible. I am especially proud of writing and maintaining the Views Bulk Operations module that eventually made its way to Drupal Core.
Service integration
Integrating with API services is an essential way for Drupal applications to interact with other systems. I have deep experience with Web APIs, on both consumer and producer sides. On the consumer side, resilience, robustness and fault-tolerance are key. I have developed several strategies to design modules that consume APIs safely and efficiently, without endangering the user experience. On the producer side, consistency and performance are paramount. I design APIs that conform to REST principles and minimize surprise by offering well-defined contracts and actionable feedback.
Content migration
A Web application typically never spawns from the void - it usually evolves from an earlier incarnation. I have conducted content migrations into Drupal from many sources, including foreign CMS installations, legacy databases, online writing systems, and previous Drupal versions. When I approach a migration, I focus on data completeness, comprehensive logging, and rapid iteration. I can reach deep into the Drupal API to programmatically create all the structures and objects needed for a turn-key migration, where users can start being productive without additional manual steps.
Troubleshooting and optimization
I enjoy the intellectual challenges of troubleshooting software issues and performance problems. I have assembled a set of tools and techniques to help with debugging and optimization. I approach troubleshooting using the scientific method - first gathering observations, then formulating hypotheses to explain the observations, then validating the hypotheses with examples and counter-examples. In most cases, the fix becomes trivial once a hypothesis is confirmed. Applied to the Drupal world, I have experience with Xdebug and other debugging controls, and I have diagnosed and fixed many issues with the notoriously tricky caching system, as well as the search API, the theming layer, and others.
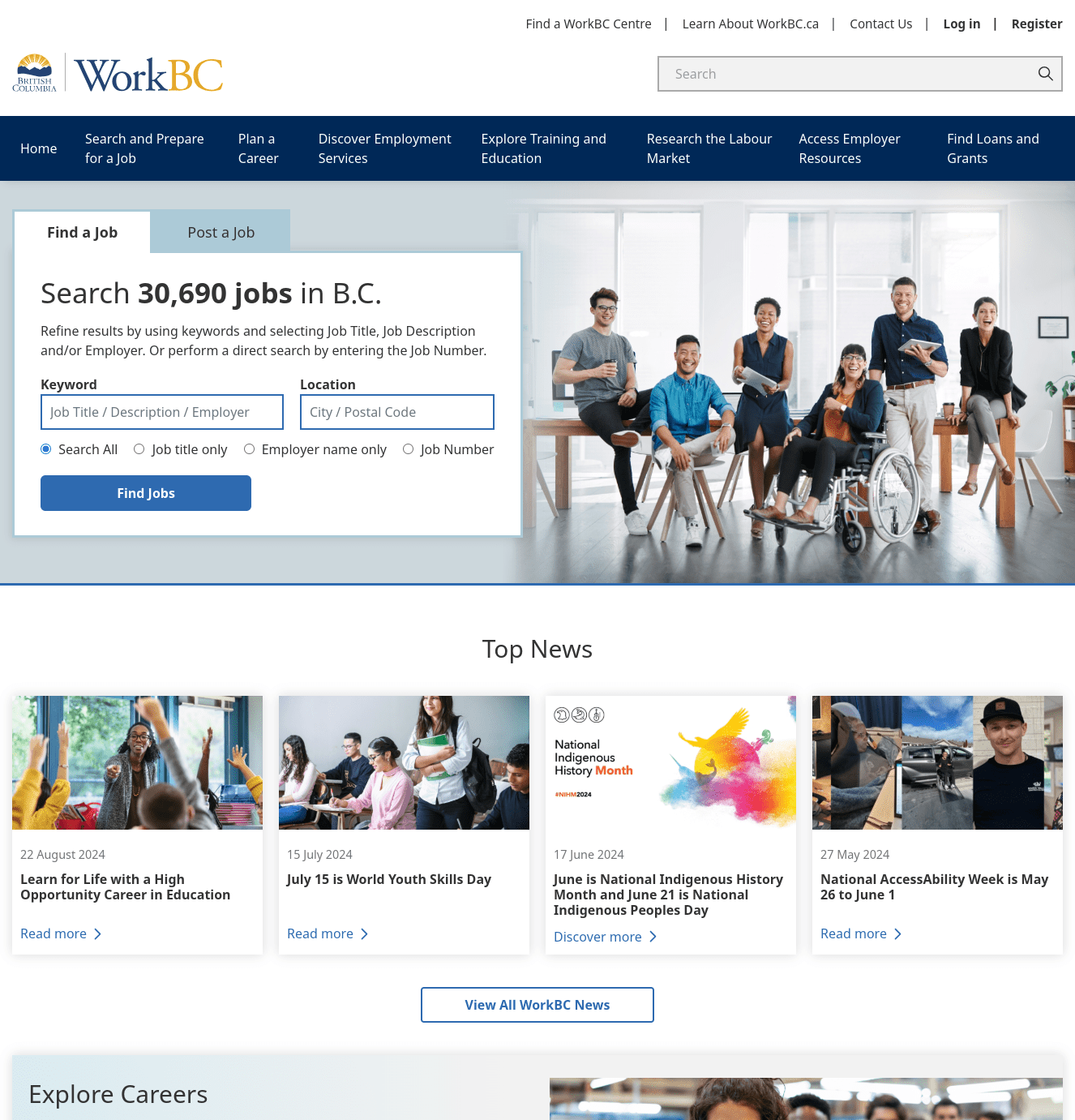
WorkBC.ca: Engineering a massive Drupal site
I played the role of Solution Architect and Team Lead to build and maintain the WorkBC.ca site. WorkBC is a service of the British Columbia Ministry of Post-Secondary Education and Future Skills, providing the 5+ million citizens of the Province with the tools needed to upgrade their professional skills and to find employment. This is a massive Drupal 10 site that utilizes the CMS to the fullest, and our small development team has solved many challenges over the past 2 years to bring it to production and ensure its continued evolution.
Technically, we’ve built some ambitious features and capabilities into this site:
Using the Drupal API, we developed robust content migration scripts to populate the CMS from various legacy sources, including GatherContent (now called Content Workflow by Bynder), Kentico CMS, etc. The multi-step, sitemap-driven migration pipeline we developed allowed us to rapidly iterate over the import scripts and to rebuild the full content from scratch in minutes.
Using paragraphs module, we gave content editors a flexible way to build new pages out of reusable components such as rich content sections and specially-formatted cards.
Using extra_field module, we injected read-only data points that consume external API services and cache the results for efficient rendering using charts module and Google Charts API.
Using advanced CSS techniques, we customized page displays to adapt to various device resolutions, including a responsive mega menu and responsive tables that transform columns into rows for mobile display.
Using PhpSpreadsheet library, we automated the ingestion of data spreadsheets and built a rule-based validation mechanism that applies business rules to augment Form API validations.
Using load-testing tool Siege, we configured a multi-machine load-testing setup to measure the application’s response to 1000+ concurrent visitors, and tune the app server accordingly.
To accommodate a rotating development team with mixed competencies, I spent a lot of time refining the developer’s experience to minimize friction:
Building a cross-platform Docker Compose environment that spins up the full application with a single docker-compose up command and clear instructions.
Building a set of tools to quickly synchronize or reset the local stage from production data dumps, including adding PostgreSQL support to backup_migrate module.
Building the necessary configuration to run the local stage with or without caching enabled, to test and replicate higher environments’ caching settings.
Documenting a robust setup to debug the application using Xdebug from within IDEs such as Visual Studio Code.
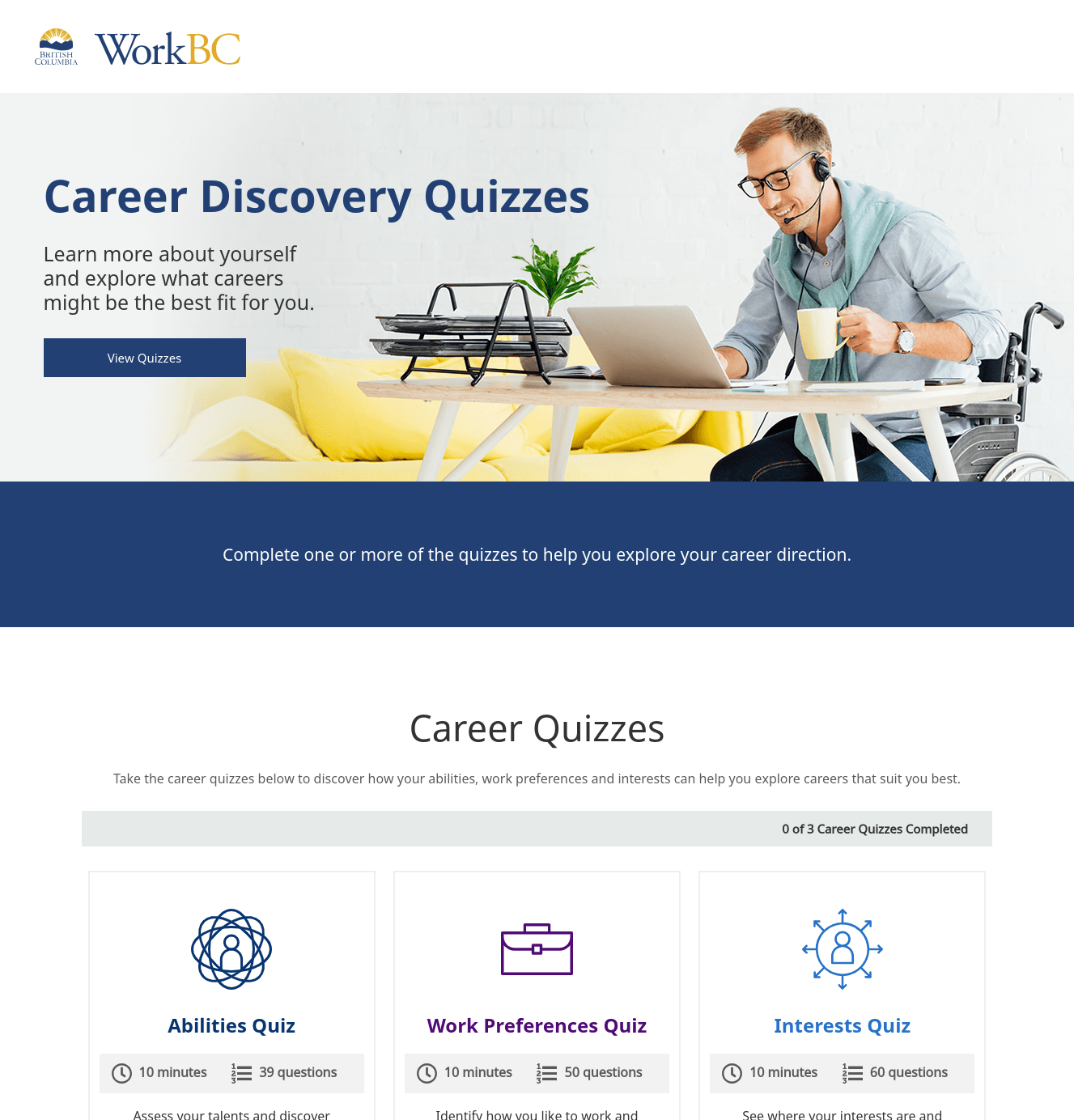
In my role of Solution Architect and Team Lead for the WorkBC portfolio, I led the re-architecture and re-implementation of the Career Discovery Quizzes (CDQ) web application. Our team inherited this codebase from a previous vendor, but we soon found out that maintaining and enhancing the existing codebase would become prohibitively costly for our government client. I flagged to the client the associated risks early on, but it took nearly a year and many hours of bug fixing to obtain a greenlight for the re-engineering of the application. In the end, what convinced the client was our ability to trace the multitude of bug tickets that kept cropping up, and the high cost of fixing each, back to the core reason: The existing codebase had been poorly architected and poorly engineered.
Here are a few red flags when evaluating Drupal codebases:
Lack of adherence to the “Drupal Way”
There are standards and best practices that guide Drupal development - many respected members of community have written about them. In our case, the core functionality of the app - namely, presenting quizzes to the public, had been created from scratch instead of leveraging the established, mature, incredibly well-supported Webform module. This was the core architectural flaw from which all other problems emanated. It also indicated that the developers of the original application had little “cultural” knowledge of the Drupal ecosystem.
Poor usage of Drupal core architecture
In their attempt to recreate a quiz engine from scratch, the original developers misused the core Drupal data structures, thereby causing undue stress on system resources such as database storage and server memory. One glaring example was the abuse of the Taxonomy system to store quiz answers - leading to an ever-increasing database table of tags - which were not actual tags to being with. By the time we inherited the codebase, the production database had inflated to hundreds of megabytes just because of this one table.
Lengthy, entangled and under-documented custom code
The truly bespoke business logic of CDQ - the only part that truly deserves custom code - is the quiz scoring mechanism. Each of the 6 quizzes presented in this application has its own scoring logic. In addition, 3 of these quizzes are expected to use their scores to match pieces of content on the site - namely, careers that correspond to visitors’ quiz answers. The original developers had written a single, giant function that enfolded the logic for all these different considerations - a function that ended up running 1000+ lines with almost no documentation and many, many different code paths. It took our team many hours to even make sense of this custom code, let alone become productive in maintaining and enhancing it.
Inability of business admins to customize content elements
Because most of the quiz engine had been hard-coded, it was not possible for the administrators of the site - the business users - to customize the content that is presented to the public, such as the formulation of quiz questions, answer options, etc. Every change needed the developers to step in, and to conduct a full round of code deployment to reach the public. This cycle was inefficient and frustrating to the whole team.
Poor performance and frequent site outages under load
The misuse of Drupal architecture and excessive custom coding led to recurrent site outages, especially given the spike nature of the application’s usage. Constant readjustment and increase of hosting resources was a patch that was becoming too budensome for the client’s IT department, who were as eager as our team to address the root cause of the maintenance burden.
Our solution: Complete re-engineering
It was with a heavy heart and a deep sense of frustration that we reached the conclusion that the original application was unsalvageable. The sheer number of tickets filed against the running application, and our analysis of each ticket leading back to poor engineering choices eventually resonated with the client who agreed to a complete rewrite.
We were extremely productive in reproducing the core functionality of the application. The Webform module allowed us to instantly recreate all quizzes, and to provide to business users the flexibility needed for them to fine-tune many aspects of how quiizes appear to the public.
We were also careful to re-engineer the quiz scoring and content matching algorithm in a modular and Drupal-friendly way. By leveraging Webform API hooks, we only performed the expensive computations when absolutely necessary. We saved matching results in our own table that we exposed to Views via Views API hooks, thereby using the familiar Drupal site building techniques to show result listings.
In total, we spent around 2 FTE-months to recreate this site, and since then the application has been running much more smoothly that it had ever before. You can find the source code of the application on GitHub.
SSOT: Creating a data API for Drupal consumption
The British Columbia Ministry of Post Secondary Education and Future Skills (PSFS) studies the labour market in our province, and produce periodic reports that include metrics about the current state and forecasted changes. For example: What’s the employment change this month among 25-54 year-olds? How does this month’s unemployment rate in Vancouver Island compare to same time last year? What are the high-opportunity careers that are currently in demand?
In my role of Solution Architect and Team Lead for the WorkBC.ca portfolio, I lead the development team whose task is to ingest those reports and publish them on the various sites and micro-applications that make up the WorkBC ecosystem. When we inherited this portfolio from a previous vendor, this statistical dataset was being stored in a duplicated, massive, highly normalized MSSQL database that was expensive to update, to host, and to consume. One of my first tasks was to architect an alternative solution that would serve as the single source of truth for PSFS data across WorkBC.ca properties. My strategy was to radically simplify the problem in order to avoid the pitfalls of the existing solution. Thus was born SSOT, the data service that currently powers all WorkBC.ca sites.
My first decision was to avoid normalizing the incoming reports. Instead of recreating an enteprise data model for the underlying entities, I decided to store the reports almost verbatim in the database. This decision, although counter-intuitive and seemingly short-sighted, has served us well for the past 2+ years and has stood the test of time as new reports are being added to the dataset. It has reduced the complexity of ingesting, querying and serving the data to almost none. We simply read in a report table to display it on the relevant page(s), at most filtering by a single column when showing a detail page.
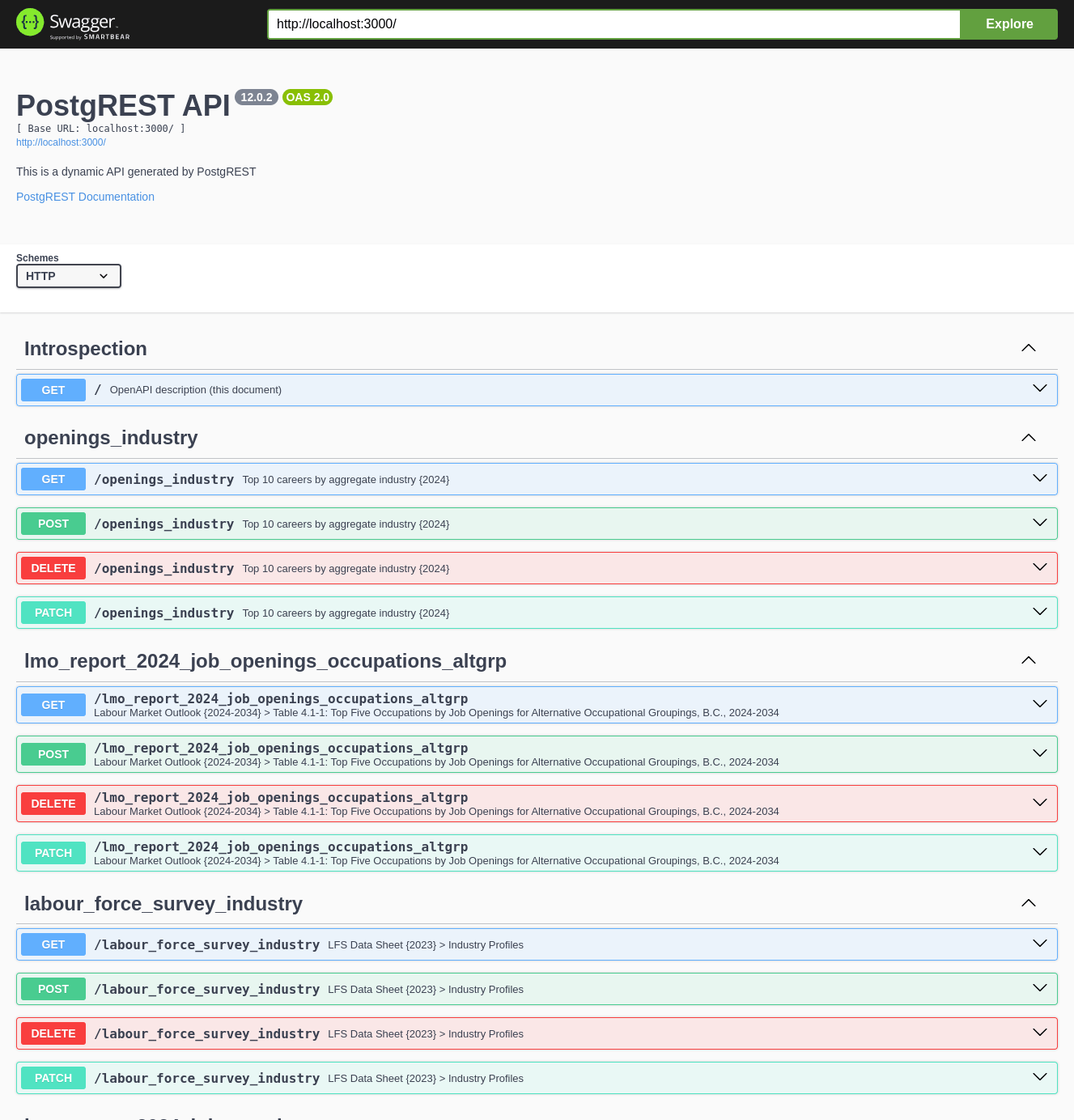
My second decision was to avoid hand-coding an API to serve these reports. I identified a flexible and mature open source data layer called PostgREST that exposes a PostgreSQL database as a REST API - with each table and view as a separate endpoint, translating the standard HTTP verbs GET/POST/PUT to the corresponding SQL SELECT/INSERT/UPDATE commands. In a very short time, we were able to start serving data to Drupal and other CMS consumers via an API layer and 2+ years later, we’ve never yet had to hack into this layer or even open bug tickets on their GitHub repo.
My third decision was to reduce the ETL process to its simplest possible form. After researching many ETL solutions, ranging from hosted commercial offerings to sophisticated Apache-based behemoths, I was overwhelmed with the complexity / cost / effort of maintaining such solutions. Instead, I opted for a custom ingestion pipeline that is inspired by the Unix philosophy of assembling single-purpose console tools into shell scripts that can recreate the full dataset in a repeatable, idempotent manner. The great majority of those tools are themselves open source, including Gnumeric’s ssconvert for Excel conversion to CSV, csvq for SQL-like manipulation of CSV files, pgloader for loading CSVs into PostgreSQL. The simplicity of this pipeline provides a solid foundation to build more ambitious functionality, such as a GitHub workflow that automatically rebuilds the full dataset when reports are updated or added to the data repository.
The following diagram illustrates the SSOT ingestion pipeline for a single report, from source Excel to REST API:
Once the SSOT data service was in place, consuming it from Drupal applications became a simple affair. Depending on the intended use of the various reports, we implemented their consumption in one of a few ways:
For display-only data points, we used the extra_fields module to create custom node fields that would load their data from SSOT on demand, and use regular theming infrastructure to format the data. To avoid unnecessary data reloads, we used hook_node_view to query the SSOT API - this hook is subject to regular Drupal caching.
The approach above does not allow filtering and sorting SSOT data, since custom fields are only populated at the rendering phase of the Drupal page request. For cases where SSOT data is needed to filter and sort listings (i.e. using the Views infrastructure), we opted for a deeper integration whereby actual storage-bound content fields get refreshed by SSOT data on a periodic basis. A dedicated hook_cron function detects that SSOT data has been updated (via a “last updated date” mechanism) and triggers a background Queue Worker job that downloads the updated dataset from SSOT and refreshes the target fields accordingly. This fully-automated update mechanism has been succesfully deployed and productionized on several Drupal applications in the portfolio.
Throughout my career, I’ve enjoyed leading small technical teams to work collaboratively towards a common goal, to produce a result we can be proud of. As a technical leader, I focus on empowering each team member to give their best in their respective skills. This begins with careful selection of team members based on the needs of the project, followed by a comprehensive briefing about project goals and parameters. Collectively, we come to an agreement on a software process to follow and each member’s roles and responsbilities in it. I am a big believer in supplying a consistent and seamless development experience for the whole team, which is achievable using a careful implementation of Docker-based environments. I emphasize clear communication and consistent usage of configuration management tools, including issue trackers, version control systems, and continous integration/deployment. I also believe in shielding the developers from the product owners, whereby I act as single point of contact to understand the business requirements and translate them to technical specifications, typically in the form of tickets and verbal briefings.